
Recently one of our customers experienced a number of performance related issues. These tended to be demonstrated during periods when the customer was running batch-type activities during the working day, clashing with the online user load. Due to business requirements rescheduling the batch work to out of hours was not an option, so a workable solution was required.
The database is Oracle version 11.2.0.3 with a 60Gb System Global Area (“SGA”) and 40GB Program Global Area (“PGA”) running on a virtual server with 16 CPU cores, 128Mb RAM and using the Oracle Linux 5.8 operating system (“OS”). The OS uses huge pages, hence sga_target rather than memory_target is used in Oracle’s initialisation parameters, and the virtualisation platform is Oracle VM.
Initial analysis was performed with Oracle Enterprise Manager (OEM) and showed the following load profile during an affected period:

On face value, this would look to be a pretty typical storage IO issue, the blue on the above graph being dominant and showing IO to be circa 65% of all wait time in the database. However, the issue only affected online user performance during the periods where we see “red” on the graph. This is related to concurrency waits on blocking locks.
After running some targeted tests set up to replicate the scenario over a sustained period of time, we saw the following:
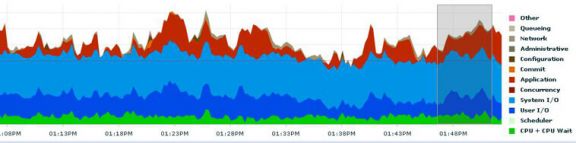
Eventually under this load the system would get to a state where it ran out of redo space and the infamous “checkpoint incomplete” error message occurred. It was also noted that the blocking locks were sessions waiting on the “ckpt” background process, producing, amongst others, the “enq KO: Fast Object Checkpoint” wait event.
A checkpoint is a point in time, before which all dirty buffers associated with historical SCNs (or System Change Numbers) have been written to the physical data files and the datafile headers and controlfiles are updated to record this SCN. The checkpoint incomplete error occurs when the next redo log group is still awaiting the write of some dirty buffers (those which have changed) associated with the log group’s redo data. The database hangs completely until the redo log group becomes available or until another empty one is added.
In this instance, the system had 25 1Gb redo log groups, so over a period of time 25Gb of redo had been generated before it was able to be written to disk. A slow IO subsystem was looking likely considering the nature of the performance graphs OEM gave us. However, something wasn’t quite stacking up – the time it took to force the database into this state was ample to write this size of data to data files under normal circumstances.
The issue was actually related to a new feature in Oracle 11g – fast object checkpointing. Fast object checkpointing is a mechanism intended to improve performance of direct path reads on data objects. A direct path read can only occur when there are no dirty buffers associated with the data block in memory – otherwise it would be data-inconsistent, or not actually a direct read. Therefore a fast object checkpoint will attempt to checkpoint all changes on an object-by-object basis rather than sequentially through SCN. This is to cut down on unnecessary duplicated writes to disk of buffer changes in the event of direct reads occurring.
We found the redo log groups were remaining active (i.e. the changes stored in them had not been written to datafiles) longer than seemed desirable. The large SGA has the ability to cache large amounts of data and since the database was also large (circa 3.5Tb), this data often pertained to the same object. Therefore a single direct read request on such an object caused the writing of all the blocks for a specific object to disk before completing a checkpoint. We saw contention in buffer cache latches and eventually ran into the dreaded checkpoint incomplete error where the database hangs causing user sessions to timeout and all manner of problems.
The fix was simply to set _db_fast_obj_ckpt=FALSE in the database’s initialisation parameters. This turned off fast object checkpointing and reverted to the old fashioned style of checkpointing, regardless as to object, based on a “first come, first served” basis. This means that the checkpoints completed more quickly, allowing the database to continue processing forwards without hanging on the checkpoint incomplete message. The trade-off here was a degradation of performance in direct reads, but overall system performance was tested and found to have improved to a large degree, for example some batch processes take around 5 times less time to complete. More importantly, the system was then able to outlast sustained periods of load before redo space became a problem.
Choosing the right Managed Services Provider
If you are looking for an Oracle partner who can help you with your Oracle Managed Services and goes about it the right way and can back up the talk, then contact us. If you would like to find out more about the E-Business Suite updates or have a question, you can email us at info@claremont.co.uk or phone us on +44 (0) 1483 549004