
At Claremont, we pride ourselves on being more than a ‘keeps-the-lights-on’ managed services provider and strive to be proactive as well as reactive. Proactive support is implicit in many of Claremont’s core values – seeking to achieve “delivery excellence” and providing “great customer service”
This is all very easy to pay lip service to and to sit in meetings and pithily say that ‘Claremont are proactive’, but we really can demonstrate this in practice – proactive support is fundamentally wrapped into the day-to-day working of each and every consultant in Claremont through documented processes that we adhere to.
This is something that I call “structural proactivity”.
Let’s go through a few examples:
Primary Consultant
Anyone in a support role in Claremont – Database Administrator, developer, UNIX system administrator, Financials consultant, HCM consultant – will handle the daily churn of incidents, changes and service requests for any and all of our customers. This is our daily bread and butter – password resets, applying patches, looking at performance issues, clones, helping with Payroll processing or month end, writing new reports or enhancing others.
Over and above that, however, each support service line will have a dedicated, named ‘Primary’ Consultant for any one of the customers we support. What does a ‘Primary’ consultant do and what benefit do they deliver for our customers?
- Point of first contact - Each customer knows who their Primary is and can contact that person via phone, email or instant messenger outside of the formal incitement management/service desk at any time. This could just be a quick chat for something not really necessary to raise an actual ticket for, some advice or question on wider system use or even an escalation of a critical issue. Sometimes those discussions will then go on to form a new incident, service request or change, but we are not one of those suppliers that will insist upon some formal ticket being logged, if you just want to pick up the phone and have a conversation with a human being!
- Subject matter expert - All support consultants will have some experience of all systems simply through working on the daily churn of incidents, but the Primary consultant will have an in-depth knowledge for their customer systems with a full knowledge of its history, current setup and future directions. If a long-running or complex problem or request comes into the Service Desk, then typically that will be fielded off to the Primary.
- Documentation - We certainly do not want all of this knowledge to be kept in people’s heads and for the Primary to become a single point of failure, so one of the Primary’s key responsibilities is keeping all documentation up-to-date and fully populated – operations guides, passwords, customer contacts, common tasks, clone procedure, patching processes and release management procedures.
- Problem analysis - Imagine an incident is raised on a Monday – the person dealing with that incident picks it up and resolves it. Then a second incident is raised the next day; the root cause is the same, but this time another person on the service desk picks it up and resolves it. Perhaps the problem happens every week or every month. If different users raise the incidents and different people within Claremont are fixing them, how then can we know that in fact all of those incidents were as a result of the same underlying issue and that further investigation is required to analyse and fix the problem at source to stop it from continuing? This is where a review of historic incidents is another defined responsibility of the Primary Consultant role. On a monthly basis the Primary Consultant will scan through all incidents raised for their customer and see if there are any trends, any problems that keep on repeating. This could then result in the creation of a Problem Record; or perhaps a change to the documented clone process; maybe a Service Request needs to be raised with Oracle or the application vendor or it could even be a user that needs to be trained or educated to do something in a different way.
- System Reviews. From time to time, the Primary Consultant will take a step back and review their customer systems ‘in the round’. For a DBA this could be reviewing that the current backup policy is still appropriate for the system as it grows and if there are any better tools or new features in the database that could be used.
o Capacity planning – is the database growing at a rate when storage will soon become a problem?
o Performance – are there any pain points that keep occurring and are the servers within tolerances?
o Are there any ways that the security of the system could be improved?
- Another of Claremont’s core values is to be “Open and honest” and we are certainly not in the business of trying to sell solutions to customers that they do not need or would have no business benefit. Any recommendation a Primary Consultant would make would embody another Claremont ethos, which is to provide “Positive, tangible business outcomes”.
- Projects. Any significant project – such as a major upgrade – will typically be performed by the Primary Consultant for that system.
- Attendance on Service Reviews. Onsite or on the phone, the Primary Consultant for each Service line will attend the monthly Service Reviews with the customer and the Claremont Service Manager. This helps the customer get to know their Primary and vice versa, provides a forum in which they can speak to each other and helps each Claremont consultant to get a wider view of their customer’s vision, ethos and future directions.
- In order to prevent knowledge becoming siloed into individuals, the Primary Consultant role for any one particular customer is periodically moved around within the team.
The Sentinel Process
“Sentinel” is the name of a (documented) process that Primary Consultants undertake for their customers that includes:
1) Review of Security Patch Updates:
a. what is the latest applied?
b. what is the latest available?
c. what are the recommendations?
2) Review of Oracle’s end-of-life support dates, recommendations for future upgrades
3) Any changes to Oracle support policy – new waivers for Extended Support, changes to license policies
4) Suggestions for techstack patching and functional patching
This is a lot of information to collate and we don’t need each Primary Consultant to reinvent the wheel for each of their customers, so ‘common’ information (like Oracle support dates and versions) are kept in a single repository which any of us can update and those changes are then automatically propagated to the detailed information for each individual system.
With this amount of complex information to share and communicate, we present this in a simple ‘traffic light’ table that forms one page of the Service Review Report.
This is an example for a typical 12.1.3 Oracle eBusiness Suite customer:
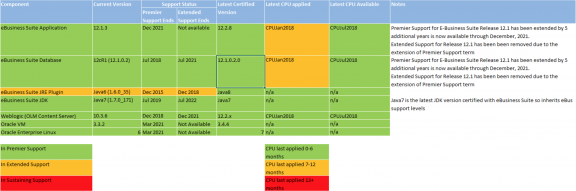
Here we can see a system that is in reasonably good shape – it could do with the latest CPU and Java upgrade and a potential Weblogic upgrade/replacement project should be considered before it leaves Premier Support.
Claremont are pragmatic and not dogmatic when it comes to these things. We will never insist that any upgrade or patch has to be applied in order for us to support any system effectively. What we will do is fully detail any risks or impact before making any system changes, providing our clients with the knowledge to make informed choices.
Technical Service Review Reports
Claremont Service Review reports contain information you would expect to see from a Service Manager, such as SLAs, KPIs, commercial summaries, key risks, achievements etc.
In addition, however, Primary Consultants feed into these reports by delivering their own technical sections each month. Sections include tables and graphs for:
- The top 20 largest segments in the database and how these have grown since the last reporting period. This is useful to learn in more detail about database growth and understand how any purging activities would be most impactful.
- The 20 longest concurrent requests over the previous reporting period for E-Business Suite systems. Are there any programs that are running for too long that need tuning? Are there times of the day or week where requests are running slower than other times?
- The total size of the database over the last reporting period and over the previous 12 months. How is the database growing over time? Is it regular or are there spikes? Has the rate of growth suddenly increased recently? What is the cause for any abnormalities?
- The database Cache hit ratios for the library cache, the database buffer cache and the dictionary cache. Are these over 90% If not, is that simply a feature of the way the application is used or are there any improvements that could be made to the database memory allocations or pinned objects to help improve these cache hit rates for performance gains?
- The I/O waits. Has the database experienced any high latency issues that could indicate a performance problem with the storage or servers? Is the system overloaded at particular times and could this be alleviated by reducing parallelism or re-scheduling jobs?
- The disk space usage and growth. Based on an analysis of the trends in the graph, at what point will a particular filesystem have exhausted its space? And what should be do about that before then?
- The server memory usage and load averages. Are the memory/CPU allocations for the machines adequate for the workload? If not, what can we do about that – performance tuning, re-scheduling jobs, increasing server capacity.
Some customers love going through the technical nitty gritty of these graphs, others don’t want to look at the detail at all and only want to know if there is anything that needs to be brought to their attention.
Generally throughout the year, graphs will show that the system is ‘all good’, but the Primary Consultant must still prepare and analyse them – Claremont processes are ‘structurally proactive’! Moreover there is still benefit in documenting the system in this way, even if everything looks rosy, since it provides an invaluable baseline should the environment suddenly start to experience abnormal growth or performance issues.
In my Own Words
I know first-hand from my own experience that collating these tables and graphs every month allows me to spot and fix potential issues before the customer is even aware of them! For example, one month the database had grown at a faster rate than normal; this was being driven by objects in the SYSAUX schema and the cause was the Statspack snapshot purge routine had stopped running – I fixed the purge job, re-ran it and by the time the Service Review came around I was able to articulate the problem and the fix!
Another time, I noticed that I/O waits suddenly increased on a particular system even through the workload was the same – this was due to a SAN migration project that the customer had completed and as a result, enabled me to provide detailed figures and graphs to show how performance had been effected based on historic values, so that the customer could raise this with their storage vendor.
In these cases I was not responding to tickets raised by the customer reporting a problem, rather I was proactively fixing issues that I noticed – very satisfying!

Kevin Behan
15th October 2018